Conseil : Que vous construisiez un fichier de données .txt, .csv ou .xml, il est nécessaire d'utiliser le nom de back-end pour les champs EMu. Vous trouverez ici des détails sur la manière de trouver le nom back-end d'un champ.
Zone des Note
- Lorsque vous construisez votre fichier Importation des données pour mettre à jour les enregistrements et que vous incluez un Nom de colonne sans lui associer de valeur, toute valeur existante dans ce champ dans EMu sera supprimée lors de l'importation. Cela peut être utile si vous souhaitez effacer toutes les valeurs existantes dans un champ particulier. Cependant, cela peut aussi être potentiellement dangereux, car vous pourriez effacer toutes les valeurs d’un champ par inadvertance.
- When following the examples in the following pages, be sure to update values to reflect spelling in your environment (for example, when specifying Party Types, change Organization to Organisation if appropriate for your EMu environment).
Trois formats de fichier sont supportés pour l'importation de données dans EMu :
- Comma Separated Values ou CSV (.csv) - Valeurs séparées par une virgule
Peut être généré en utilisant un produit comme MS Excel et en sauvegardant les fichier au format .csv.
- Valeurs séparées par des tabulations ou TSV (.txt ou .tab)
Peut être généré à l'aide d'un outil de texte, tel que Bloc-notes, ou d'un produit tel que MS Excel et l'enregistrement des fichiers en .txt.
Les mêmes règles qui s'appliquent aux fichiers .csv s'appliquent aux fichiers .txt, à l'exception du fait que les valeurs sont séparées par des tabulations plutôt que par des virgules.
 Comment Sauvegarder un fichier au format .csv ou .txt dans MS Excel
Comment Sauvegarder un fichier au format .csv ou .txt dans MS ExcelDans les exemples suivants, MS Excel est utilisé pour créer les types de fichiers .txt et .csv en sélectionnant .txt ou .csv dans la liste déroulante Enregistrer sous type dans la fenêtre Enregistrer sous :
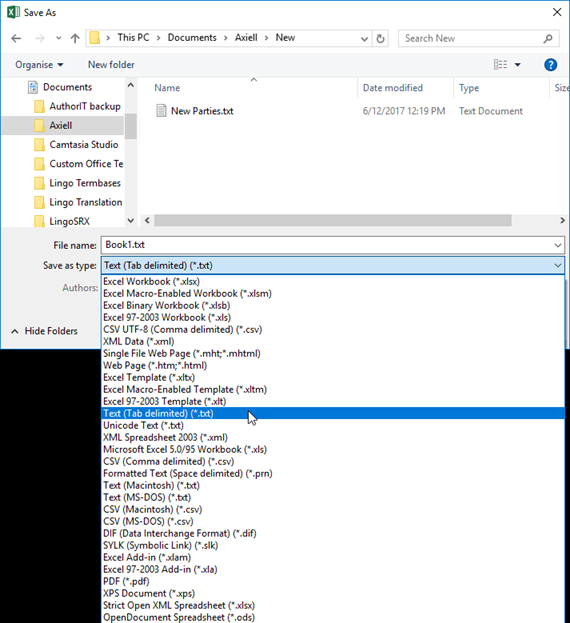
Note: MS Excel tentera d'appliquer son format de date par défaut aux valeurs formatées comme un type de données Date. Cela peut avoir des conséquences indésirables si le format de date par défaut d'Excel est différent du format que vous souhaitez. Il est donc recommandé de formater les colonnes de dates sous forme de texte plutôt que sous forme de types de données Date. Pour éviter toute ambiguïté, il est recommandé de formater également les valeurs de date comme, par exemple 24-nov-2006 (en utilisant la version texte d'un mois et d'une année complète).
- eXtensible Markup Language ou XML (.xml)
Offre la plus grande souplesse dans la spécification des données à importer et est recommandé lorsque l'outil Importer permet d'importer plus que les structures de données les plus basiques (par exemple, lorsque vous spécifiez des enregistrements avec des pièces jointes, des tables imbriquées, etc.)
Une méthode simple pour générer le XML correctement structuré pour les champs que vous souhaitez importer ou mettre à jour dans EMu est de créer un rapport XML dans EMu :
- Dans le module dans lequel les données doivent être importées ou mises à jour, créez un rapport Document XML et incluez les champs à importer ou à mettre à jour.
- Exécutez le rapport. Un document XML est généré. Le format du rapport est le même que celui requis pour une importation.
Lors de l'importation de données dans EMu six types de champs peuvent être spécifiés dans un fichier de données d'importation :
- Atomique (un champ à valeur unique), par ex. Prénom : (Détails personnels) dans le module Personnes / Organisations.
- Table (un champ qui peut contenir plusieurs valeurs, une par ligne), par exemple Autres noms : (Détails personnels) dans le module Personnes / Organisations.
- Table imbriquée (une table dans une table : la table est un champ qui peut contenir plusieurs valeurs, une par ligne).
- Référence atomique (un champ à valeur unique qui fait référence à un autre enregistrement), par exemple Emprunteur ou prêteur : (Détails du prêt/emprunt) dans le module Prêts/Emprunts.
- Référence de la table (un champ qui peut contenir plusieurs valeurs, une par ligne, chacune étant une référence à un autre enregistrement), par exemple Associé avec dans le module Personnes / Organisations.
- Référence à une table imbriquée (une table dans une table : la table est un champ qui peut contenir plusieurs valeurs, une par ligne, chacune étant une référence à un autre enregistrement, par exemple Assignée à : (Informations sur la tâche) dans l'onglet Tâches (dans de nombreux modules).
4, 5 et 6 sont des variations des trois premiers et spécifient des liens vers des champs atomiques, de table et de nested table (table imbriquée) (c'est-à-dire que les champs ne contiennent pas de données mais des références à d'autres enregistrements).
Cette section présente la conception d'un fichier de données d'importation dans les trois formats supportés. L'approche est d'utiliser des exemples, chacun étant construit sur le précédent. Il est donc suggéré de pratiquer ces exemples les uns à la suite des autres.

